Ako používať regulárne výrazy na nahradenie tokenov v reťazcoch v jazyku Java
1. Prehľad
Ak potrebujeme nájsť alebo nahradiť hodnoty v reťazci v prostredí Java, zvyčajne používame regulárne výrazy. Umožňujú nám určiť, či sa niektorý alebo celý reťazec zhoduje so vzorom. Mohli by sme ľahko použiť rovnakú náhradu na viac tokenov v reťazci s nahradiť všetko metóda v oboch Matcher a String.
V tomto tutoriáli preskúmame, ako použiť inú náhradu pre každý token nájdený v reťazci. Toto nám uľahčí uspokojenie prípadov použitia, ako je uniknutie niektorým znakom alebo nahradenie zástupných hodnôt.
Pozrime sa tiež na niekoľko trikov na vyladenie našich regulárnych výrazov, aby sme správne identifikovali tokeny.
2. Individuálne spracovanie zápasov
Predtým, ako budeme môcť zostaviť náš algoritmus výmeny token-by-token, musíme porozumieť Java API okolo regulárnych výrazov. Vyriešime zložitý problém zhody pomocou skupín zachytávania a nezachytávania.
2.1. Príklad názvu nadpisu
Poďme si predstaviť, že chceme vytvoriť algoritmus na spracovanie všetkých titulných slov v reťazci. Tieto slová sa začínajú jedným veľkým písmenom a potom sa končia alebo pokračujú iba malými písmenami.
Náš vstup môže byť:
„Prvé 3 veľké slová! Potom 10 TLA, našiel som“Z definície titulného slova obsahuje zhody:
- najprv
- Kapitál
- Slová
- Ja
- Nájdené
A regulárny výraz na rozpoznanie tohto vzoru by bol:
"(? <= ^ | [^ A-Za-z]) ([A-Z] [a-z] *) (? = [^ A-Za-z] | $)"Aby sme to pochopili, rozoberme to na jednotlivé súčasti. Začneme v strede:
[A-Z]rozpozná jedno veľké písmeno.
Povoľujeme jednoznakové slová alebo slová, za ktorými nasledujú malé písmená, takže:
[a-z] *rozpozná nula alebo viac malých písmen.
V niektorých prípadoch by stačili vyššie uvedené dve triedy znakov na rozpoznanie našich tokenov. V našom ukážkovom texte sa bohužiaľ nachádza slovo, ktoré začína niekoľkými veľkými písmenami. Preto musíme vyjadriť, že jediné veľké písmeno, ktoré nájdeme, musí byť prvé, ktoré sa objaví po iných písmenách.
Podobne, keď pripúšťame slovo s jedným veľkým písmenom, musíme vyjadriť, že jediné veľké písmeno, ktoré nájdeme, nesmie byť prvé zo slova s viacerými veľkými písmenami.
Výraz [^ A-Za-z] znamená „žiadne písmená“. Jeden z nich sme umiestnili na začiatok výrazu do nezachytávajúcej skupiny:
(? <= ^ | [^ A-Za-z])Skupina nezachytávajúca, počnúc od (?<=, robí a pohľad dozadu, aby sa zabezpečilo, že sa zhoda objaví na správnej hranici. Jeho náprotivok na konci robí rovnakú prácu pre nasledujúce postavy.
Ak sa však slová dotknú úplného začiatku alebo konca reťazca, musíme to zohľadniť, a to je miesto, kam sme pridali ^ | do prvej skupiny, aby to znamenalo „začiatok reťazca alebo akékoľvek iné znaky ako písmená“, a na koniec poslednej nezachytávajúcej skupiny sme pridali | $, aby koniec reťazca mohol byť hranicou .
Postavy nájdené v skupinách, ktoré nezachytávajú, sa v zápase nezobrazia keď používame Nájsť.
Mali by sme poznamenať, že aj taký jednoduchý prípad použitia môže mať veľa okrajových prípadov, takže je dôležité vyskúšať naše regulárne výrazy. Na tento účel môžeme písať testy jednotiek, používať vstavané nástroje nášho IDE alebo používať online nástroj ako Regexr.
2.2. Testujeme náš príklad
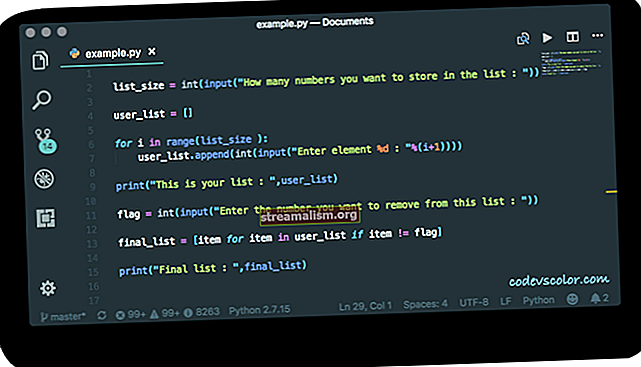
S našim príkladom text v konštante tzv EXAMPLE_INPUT a náš regulárny výraz v a Vzor zavolal TITLE_CASE_PATTERN, použijeme Nájsť na Matcher triedy na extrahovanie všetkých našich zápasov v jednotkovom teste:
Matcher Matcher = TITLE_CASE_PATTERN.matcher (EXAMPLE_INPUT); Zoznam zápasov = nový ArrayList (); while (matcher.find ()) {match.add (matcher.group (1)); } assertThat (zhoduje sa). obsahuje Presne ("Prvý", "Veľké", "Slová", "Ja", "Nájdené");Tu používame dohadzovač funkcia zapnutá Vzor vyrobiť a Matcher. Potom použijeme Nájsť metóda v slučke, kým sa neprestane vracať pravda opakovať všetky zápasy.
Zakaždým Nájsť vracia pravda, Matcher stav objektu je nastavený tak, aby predstavoval aktuálnu zhodu. Môžeme skontrolovať celý zápas s skupina (0)alebo skontrolujte konkrétne zachytávajúce skupiny pomocou ich indexu založeného na 1. V takom prípade je okolo časti, ktorú chceme, zachytávajúca skupina, ktorú teda použijeme skupina (1) pridať zápas na náš zoznam.
2.3. Inšpekcia Matcher trochu viac
Zatiaľ sa nám podarilo nájsť slová, ktoré chceme spracovať.
Ak by však každé z týchto slov bolo tokenom, ktorý sme chceli nahradiť, na vytvorenie výsledného reťazca by sme potrebovali viac informácií o zhode. Pozrime sa na niektoré ďalšie vlastnosti Matcher ktoré by nám mohli pomôcť:
while (matcher.find ()) {System.out.println ("Match:" + matcher.group (0)); System.out.println ("Štart:" + matcher.start ()); System.out.println ("Koniec:" + matcher.end ()); }Tento kód nám ukáže, kde je každá zhoda. Ukazuje nám to tiež skupina (0) zápas, čo je všetko zachytené:
Zápas: Prvý štart: 0 Koniec: 5 Zápas: Kapitálový štart: 8 Koniec: 15 Zápas: Začiatok slov: 16 Koniec: 21 Zápas: Ja štart: 37 Koniec: 38 ... viacTu vidíme, že každý zápas obsahuje iba slová, ktoré očakávame. The začať Vlastnosť zobrazuje nulový index zhody v rámci reťazca. The koniec zobrazuje index znaku hneď po. To znamená, že by sme mohli použiť podreťazec (štart, end-start) extrahovať každú zhodu z pôvodného reťazca. Takto je to v podstate skupina metóda to robí za nás.
Teraz, keď môžeme použiť Nájsť na opakovanie zápasov, spracovajme naše tokeny.
3. Výmena zápasov jeden po druhom
Pokračujme v našom príklade tak, že náš algoritmus nahradí každé slovo v pôvodnom reťazci ekvivalentom malých písmen. To znamená, že náš testovací reťazec bude prevedený na:
„prvé 3 veľké slová! potom 10 TLA, našiel som“The Vzor a Matcher trieda to za nás nemôže urobiť, takže musíme skonštruovať algoritmus.
3.1. Náhradný algoritmus
Tu je pseudokód algoritmu:
- Začnite prázdnym výstupným reťazcom
- Pre každý zápas:
- Pridajte do výstupu všetko, čo prišlo pred zápasom a po ktoromkoľvek predchádzajúcom zápase
- Spracujte túto zhodu a pridajte ju k výstupu
- Pokračujte, kým sa nespracujú všetky zápasy
- Do výstupu pridajte všetko, čo zostalo po poslednom zápase
Mali by sme poznamenať, že cieľom tohto algoritmu je vyhľadajte všetky nezhodné oblasti a pridajte ich do výstupu, ako aj pridanie spracovaných zhôd.
3.2. Replacer tokenov v Jave
Chceme previesť každé slovo na malé písmená, aby sme mohli napísať jednoduchú metódu prevodu:
private static String convert (reťazec token) {return token.toLowerCase (); }Teraz môžeme napísať algoritmus na iteráciu zápasov. To môže použiť a StringBuilder pre výstup:
int lastIndex = 0; Výstup StringBuilder = nový StringBuilder (); Matcher matcher = TITLE_CASE_PATTERN.matcher (originál); while (matcher.find ()) {output.append (original, lastIndex, matcher.start ()) .append (convert (matcher.group (1))); lastIndex = matcher.end (); } if (lastIndex <original.length ()) {output.append (original, lastIndex, original.length ()); } vratit vystup.toString ();Mali by sme si to všimnúť StringBuilder poskytuje praktickú verziu pridať ktoré môžu extrahovať podreťazce. Toto funguje dobre s koniec majetok Matcher aby sme si mohli vyzdvihnúť všetky nezhodné postavy od posledného zápasu.
4. Zovšeobecnenie algoritmu
Teraz, keď sme vyriešili problém s nahradením niektorých konkrétnych tokenov, prečo kód neprevedieme do podoby, ktorá sa dá použiť pre všeobecný prípad? Jediná vec, ktorá sa líši od jednej implementácie k druhej, je regulárny výraz, ktorý sa má použiť, a logika konverzie každej zhody na jej náhradu.
4.1. Použite vstup funkcií a vzorov
Môžeme použiť Java Funkcia objekt umožňujúci volajúcemu poskytnúť logiku na spracovanie každej zhody. A môžeme vziať vstup s názvom vzor tokenu nájsť všetky tokeny:
// rovnako ako predtým while (matcher.find ()) {output.append (original, lastIndex, matcher.start ()) .append (converter.apply (matcher)); // rovnaké ako predtýmRegulárny výraz tu už nie je pevne zakódovaný. Namiesto toho prevodník Funkcia je poskytovaná volajúcim a je aplikovaná na každú zhodu v rámci Nájsť slučka.
4.2. Testuje sa všeobecná verzia
Pozrime sa, či funguje všeobecná metóda rovnako dobre ako pôvodná:
assertThat (replaceTokens ("Prvé 3 veľké slová! potom 10 TLA, našiel som", TITLE_CASE_PATTERN, match -> match.group (1) .toLowerCase ())) .isEqualTo ("prvé 3 veľké slová! potom 10 TLA, našiel som ");Tu vidíme, že volanie kódu je jednoduché. Funkciu prevodu je možné ľahko vyjadriť ako lambda. A test vyhovuje.
Teraz máme náhradu tokenu, tak skúsme nejaké ďalšie prípady použitia.
5. Niektoré prípady použitia
5.1. Unikajúce špeciálne znaky
Predstavme si, že sme chceli použiť únikový znak regulárneho výrazu \ na manuálne citovanie každého znaku regulárneho výrazu namiesto na použitie znaku citovať metóda. Možno citujeme reťazec ako súčasť vytvárania regulárneho výrazu, ktorý sa má odovzdať do inej knižnice alebo služby, takže blokové citovanie výrazu nebude stačiť.
Ak môžeme vyjadriť vzor, ktorý znamená „znak regulárneho výrazu“, je ľahké pomocou nášho algoritmu uniknúť všetkým:
Pattern regexCharacters = Pattern.compile ("[]"); assertThat (replaceTokens ("Znak regulárneho výrazu ako [", regulárne výrazy, zhoda -> "\" + match.group ()))) .isEqualTo ("Znak regulárneho výrazu ako \ [");Pre každý zápas dávame predponu \ znak. Ako \ je špeciálny znak v reťazcoch Java, unikol s iným \.
Tento príklad je v skutočnosti zahrnutý navyše \ znaky ako trieda znakov vo vzore pre regexPostavy musí citovať veľa špeciálnych znakov. Toto ukazuje syntaktický analyzátor regulárneho výrazu, že ho používame na označenie ich literálov, nie ako syntax regulárneho výrazu.
5.2. Výmena zástupných znakov
Bežným spôsobom, ako vyjadriť zástupný symbol, je použitie syntaxe typu $ {name}. Zvážme prípad použitia šablóny „Ahoj $ {name}, $ {company}" je potrebné vyplniť z mapy s názvom zástupné hodnoty:
Map placeholderValues = new HashMap (); placeholderValues.put ("meno", "účet"); placeholderValues.put ("spoločnosť", "Baeldung");Potrebujeme len dobrý regulárny výraz nájsť ${…} žetóny:
"\ $ \ {(? [A-Za-z0-9 -_] +)}"je jedna možnosť. Musí to citovať $ a počiatočná zložená zátvorka, pretože by sa inak považovali za syntax regulárneho výrazu.
Srdcom tohto vzoru je skupina zachytávajúca meno zástupného symbolu. Použili sme triedu znakov, ktorá umožňuje alfanumerické znaky, pomlčky a podčiarkovníky, ktoré by sa mali hodiť pre väčšinu prípadov použitia.
Avšak kvôli lepšej čitateľnosti kódu sme túto skupinu zachytilizástupný symbol. Pozrime sa, ako používať túto pomenovanú skupinu snímania:
assertThat (replaceTokens ("Hi $ {name} at $ {company}", "\ $ \ {(? [A-Za-z0-9 -_] +)}", match -> placeholderValues.get (match .group ("placeholder")))) .isEqualTo ("Hi Bill at Baeldung");Tu vidíme, že získanie hodnoty pomenovanej skupiny z Matcher proste zahŕňa použitie skupina s menom ako vstupom, a nie s číslom.
6. Záver
V tomto článku sme sa zaoberali tým, ako používať silné regulárne výrazy na vyhľadanie tokenov v našich reťazcoch. Dozvedeli sme sa, ako Nájsť metóda pracuje s Matcher aby nám ukázali zápasy.
Potom sme vytvorili a zovšeobecnili algoritmus, ktorý nám umožnil vykonať výmenu token-by-token.
Nakoniec sme sa pozreli na zopár bežných prípadov použitia pre únikové znaky a vyplnenie šablón.
Ako vždy, príklady kódov nájdete na GitHub.