Úvod do veľkého frontu
1. Prehľad
V tomto výučbe sa rýchlo pozrieme na Veľkú frontu, implementáciu trvalého frontu v Jave.
Trochu si povieme o jeho architektúre a potom sa na rýchlych a praktických príkladoch dozvieme, ako ho používať.
2. Použitie
Budeme musieť pridať bigqueue závislosť na našom projekte:
com.leansoft bigqueue 0.7.0 Musíme tiež pridať jeho úložisko:
github.release.repo //raw.github.com/bulldog2011/bulldog-repo/master/repo/releases/ Ak sme zvyknutí pracovať so základnými radmi, bude ľahké sa prispôsobiť Veľkému frontu, pretože jeho API je dosť podobné.
2.1. Inicializácia
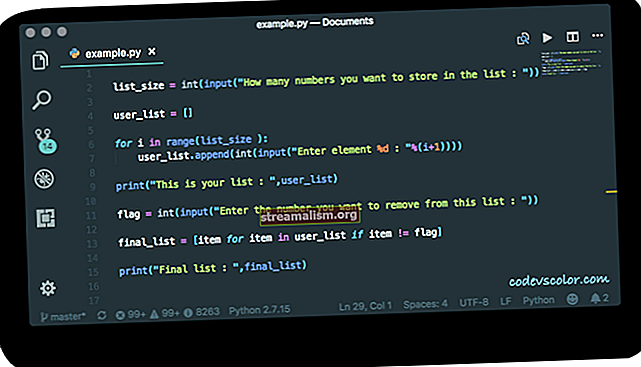
Môžeme inicializovať našu frontu zjednodušením volania jej konštruktora:
@ Pred public void setup () {String queueDir = System.getProperty ("user.home"); Reťazec queueName = "baeldung-queue"; bigQueue = nový BigQueueImpl (queueDir, queueName); }Prvým argumentom je domovský adresár pre náš front.
Druhý argument predstavuje názov nášho frontu. Vytvorí priečinok v domovskom adresári nášho frontu, kde môžeme uchovať údaje.
Mali by sme pamätať na to, že po dokončení budeme rad uzavrieť, aby sme zabránili úniku pamäte:
bigQueue.close ();2.2. Vkladanie
Môžeme pridať prvky na chvost jednoduchým volaním zaradiť do poradia metóda:
@Test public void whenAddingRecords_ThenTheSizeIsCorrect () {for (int i = 1; i <= 100; i ++) {bigQueue.enqueue (String.valueOf (i) .getBytes ()); } assertEquals (100, bigQueue.size ()); }Mali by sme poznamenať, že Big Queue podporuje iba byte [] dátový typ, takže sme zodpovední za serializáciu našich záznamov pri vkladaní.
2.3. Čítanie
Ako sme mohli čakať, čítanie údajov je rovnako jednoduché pomocou dequeue metóda:
@Test public void whenAddingRecords_ThenTheyCanBeRetrieved () {bigQueue.enqueue (String.valueOf ("new_record"). GetBytes ()); Záznam reťazca = nový reťazec (bigQueue.dequeue ()); assertEquals ("nový_záznam", záznam); }Musíme tiež dávať pozor, aby sme pri čítaní správne deserializovali svoje údaje.
Čítanie z prázdneho frontu vyvolá a NullPointerException.
Mali by sme overiť, či sú v našom rade hodnoty, pomocou znaku je prázdny metóda:
if (! bigQueue.isEmpty ()) {// prečítať}Na vyprázdnenie nášho frontu bez nutnosti prechádzania jednotlivých záznamov môžeme použiť odobrať všetky metóda:
bigQueue.removeAll ();2.4. Kukanie
Pri nahliadnutí jednoducho prečítame záznam bez toho, aby sme ho spotrebovali:
@Test public void whenPeekingRecords_ThenSizeDoesntChange () {for (int i = 1; i <= 100; i ++) {bigQueue.enqueue (String.valueOf (i) .getBytes ()); } Reťazec firstRecord = nový Reťazec (bigQueue.peek ()); assertEquals ("1", firstRecord); assertEquals (100, bigQueue.size ()); }2.5. Mazanie spotrebovaných záznamov
Keď voláme dequeue metóda, záznamy sa odstránia z nášho frontu, ale na disku zostanú trvalé.
Mohlo by to potenciálne zaplniť náš disk nepotrebnými údajmi.
Našťastie môžeme vymazať spotrebované záznamy pomocou gc metóda:
bigQueue.gc ();Rovnako ako zberač odpadu v Jave čistí nereferované objekty z haldy, gc čistí spotrebované záznamy z nášho disku.
3. Architektúra a funkcie
Čo je na Big Queue zaujímavé, je skutočnosť, že jeho kódová základňa je extrémne malá - iba 12 zdrojových súborov zaberá asi 20 kB diskového priestoru.
Na vysokej úrovni je to len vytrvalý rad, ktorý vyniká pri spracovaní veľkého množstva údajov.
3.1. Spracovanie veľkého množstva údajov
Veľkosť frontu je obmedzená iba našim celkovým dostupným diskovým priestorom. Každý záznam v našom rade je uložený na disku, aby bol odolný voči pádu.
Našim úzkym miestom bude disk I / O, čo znamená, že SSD disk výrazne zlepší priemernú priepustnosť cez HDD.
3.2. Prístup k údajom mimoriadne rýchly
Ak sa pozrieme na jeho zdrojový kód, všimneme si, že front je zálohovaný súborom mapovaným do pamäte. Prístupná časť nášho frontu (hlava) je uchovávaná v RAM, takže prístup k záznamom bude mimoriadne rýchly.
Aj keby sa náš front extrémne zväčšil a zaberal by terabajty miesta na disku, stále by sme boli schopní čítať údaje v časovej zložitosti O (1).
Ak potrebujeme prečítať veľa správ a rýchlosť je kritickým problémom, mali by sme zvážiť použitie disku SSD cez pevný disk, pretože presun údajov z disku na pamäť by bol oveľa rýchlejší.
3.3. Výhody
Veľkou výhodou je jeho schopnosť dorásť do veľmi veľkých rozmerov. Môžeme ju zväčšiť na teoretické nekonečno iba pridaním väčšieho úložiska, a preto má názov „Veľký“.
V súbežnom prostredí môže Big Queue na komoditnom stroji vyprodukovať a spotrebovať okolo 166 MBps dát.
Ak je naša priemerná veľkosť správy 1 kB, môže spracovať 166 000 správ za sekundu.
V prostredí s jedným vláknom dokáže odoslať až 333 000 správ za sekundu - veľmi pôsobivé!
3.4. Nevýhody
Naše správy zostávajú trvalé na disku, a to aj potom, čo sme ich spotrebovali, takže sa musíme postarať o zhromažďovanie údajov, keď ich už nepotrebujeme.
Sme tiež zodpovední za serializáciu a deserializáciu našich správ.
4. Záver
V tomto rýchlom výučbe sme sa dozvedeli o Veľkej fronte a o tom, ako ju môžeme použiť ako škálovateľný a perzistentný front.
Ako vždy, kód je k dispozícii na stránkach Github.